Behind the pretty HTML cover of Allure Report is the idea that QA should be the responsibility of the entire team, not just QA – which means that test results should be accessible and readable by people without the QA or dev skill set. Report allows you to move past the details that don’t help you, staying at your preferred level of abstraction – and yet if you do need to drill into the code, it’s just a few mouse clicks away.
Report achieves this basic goal by being language-, framework-, and tool-agnostic. It can hide the peculiarities of your tech stack because it doesn’t depend upon it. So how does one become agnostic? You can’t do it through magic, you have to write tons of integrations, literally hundreds of thousands lines of code to integrate with anything and everything. Allure Report is a hub of integrations, and its structure is designed specifically with the purpose of making new integrations easier.
Let’s imagine that we’re writing a new integration for Report, and look at what resources we can leverage to make our job easier. We will be comparing how much effort we need to apply with Report and with other tools. We will start with the most straightforward advantages – the existing codebase; and then talk about more fundamental stuff like architecture and knowledge base.
Selenide native vs Selenide in Allure Report
To begin with, let us compare native reporting for Selenide with the way Selenide is integrated in Allure Report, and then see how difficult it was to write the integration for Report.
While creating simple reporting for Selenide is relatively easy, it’s a completely different story if you want to make quality test reports. In JUnit, there is only one extension point – the exception that is being thrown on test failure. You can jam the meta-information for the report into that exception, but working with this information will be difficult.
By default, Selenide and most other tools take the easy road. When Selenide reports on a failed test, what you get is just the text of the exception, a screenshot, and the HTML of the page at the time of failure:
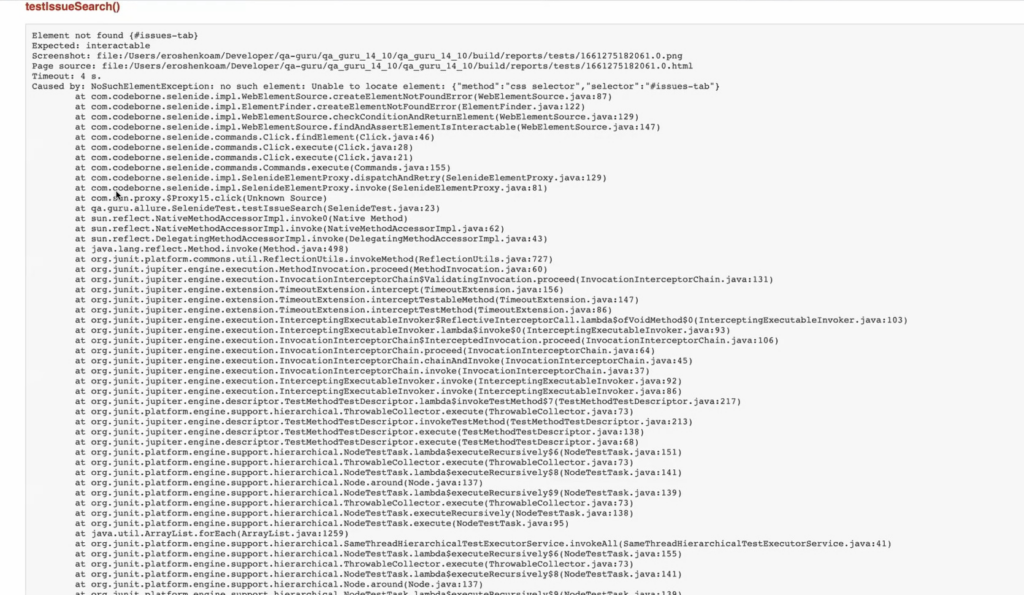
If you’re the only tester on the project and all the tests are fresh in your memory, this might be more than enough – which is what the developers of Selenide are telling us.
Now, let’s compare this to Allure Report. If you run Report on a Selenide test with nothing plugged in, you’ll get just the text of the exception, same as with Selenide’s report.
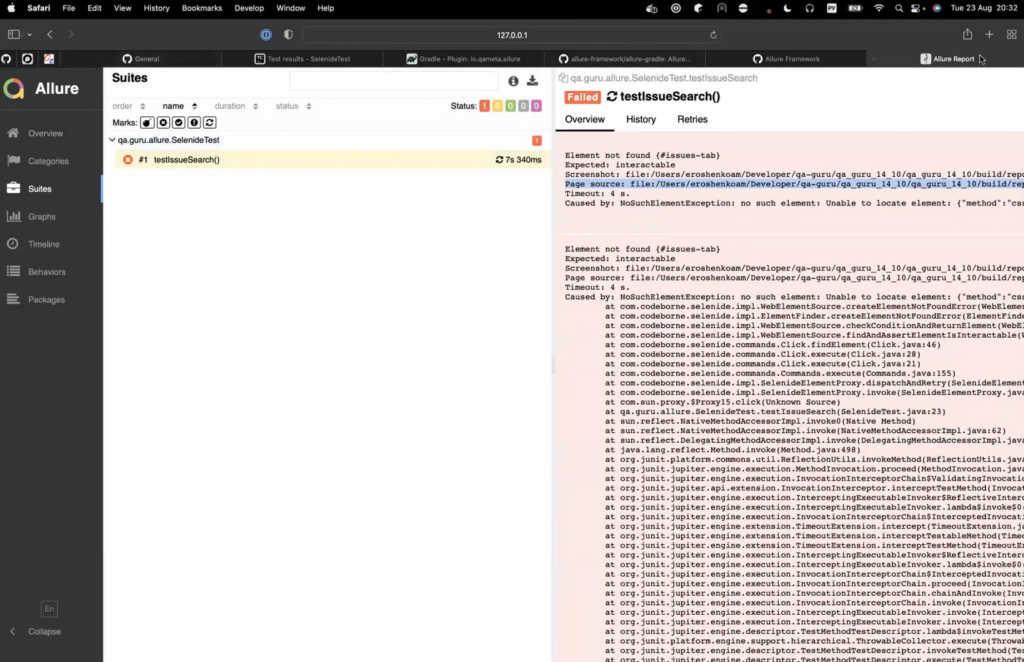
But, as I’ve said before, the power of Allure Report is in its integrations. Things will change if we turn on allure-selenide and an integration for the framework you’re using (in this case – allure-junit). First (this is specific to the Selenide integration), we’re going to have to add the following line at the beginning of our test (or as a separate function with a @BeforeAll annotation):
SelenideLogger.addListener(“AllureSelenide”, new AllureSelenide());
Now, our test results have steps in them, and you can see precisely where the test has failed:
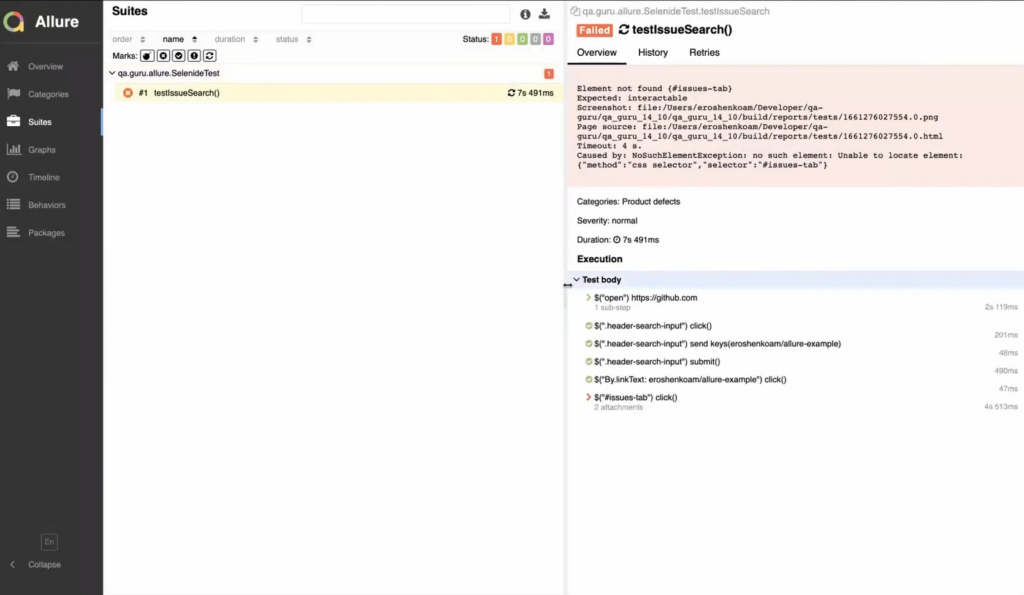
This can help you figure out why the test failed (whether the problem is in the test or in the code). You also get screenshots and the page source. Finally, with these integrations, you can wrap the function calls of your test inside the step() function or use the @Step annotation for functions you write yourself. This way, the steps displayed in test results will have custom names that you’ve written in human language, not lines of code. This makes the test results readable by people who don’t write Java (other testers, managers etc.). Adding all the steps might seem like a lot of extra work, but in the long run it actually saves time, because instead of answering a bunch of questions from other people in your company you can just direct them to test results written in plain English.
This is powerful stuff compared to what Selenide (and most other tools) offer as default reports. So here’s the main question for this article: how much effort did it take to achieve this? The source code for the allure-selenide integration is about 250 lines long. Considering the functionality that this provides, that’s almost nothing. Writing such an integration would probably be as easy as providing the bare exception that we get if we use Selenide’s native reporting.
This is the main takeaway: a proper integration with Allure Report takes about as much effort as a quick and easy integration with other tools (provided we’re talking about a language where Report has an established code base, such as Java or Python). How is that possible?
Common Libraries
The 250 lines of code in allure-selenide leverage files with about 500 lines of code from the allure-model section of allure-java, and about 1300 lines from allure-java-commons. These common libraries have been created to ease the process of making new integrations – and there are more than a dozen for Java alone that utilize these common libraries.
Writing these libraries is not a straightforward task. There are problems of execution here that can be extremely difficult to solve. For instance, when writing the allure-go integration, Anton Sinyaev spent several months solving the issue of parallel test execution (an issue which was left unsolved for 8 years in testify, the framework from which allure-go was forked). Such problems can be unique for a particular framework, which makes writing common libraries difficult. Generally speaking, once the process has been smoothed out, writing an integration for a framework like JUnit might take a month of work; but if there are no common libraries present, you could be looking at 4 or 5 months.
The JSON with the results
Let’s go deeper. What if we’re writing an integration for an entirely new language? Since the language is different, none of the code can be reused. Here, the example with Go is particularly telling, since it is quite unlike Java or Python, both in basic things like lack of classes, and in the way it works with threads. Because of this, not only was it not possible to reuse the code, but even the general solutions couldn’t be translated from one language to another. Then what HAS been reused in that case?
Arguably the most important part of Allure Report is its data format, the JSON file which stores the results of test runs. This is the meeting point for all languages, the thing that makes Allure Report language-agnostic. Designing that format took about a year, and it has incorporated some major architectural decisions – which means if you’re writing a new integration, you no longer have to think about this stuff. Thanks to this, the first, raw version of allure-go was written over a weekend – although it took several months to solve problems of execution and work out the kinks.
Experience
Finally, there is the least tangible asset of all – experience. Writing integrations is a peculiar field of programming, and a person skilled in it will be much more productive than someone who is just talented and generally experienced. If one had to guess, it would probably take 10 people about 2–3 years to re-do the work that’s been done on Allure Report, with one developer for each of the major languages and its common libraries, 2 or 3 devs for the reporter itself, an architect, and someone to work with the community.
Community
Allure Report’s community is not an asset strictly speaking, but when creating a new integration, it actually provides an extremely important role in several ways.
- DEMAND. As we’ve already said, adding test reporting to a framework or a tool can take months of work if done properly. If you’re doing this purely for your own comfort, you’ll probably cut a lot of corners, do things quick and dirty. If, on the other hand, you’re working on something that is going to be used by millions of people, that’s motivation enough to sit around for an extra month or two and provide, say, proper parallel execution of tests.
- EXPERIENCED DEVELOPERS. Here, we’re kind of returning to the previous section: the open-source nature of the tool allowed Qameta to get in touch with plenty of developers experienced in writing integrations, and hire from that pool.
- THE INTEGRATIONS THEMSELVES. Allure report didn’t start out as a tool designed to integrate with anything and everything – the first version was just built for Junit 4 and Python. Pretty much everything outside allure-java and allure-python was initially developed outside Qameta, and then verified and internalized by the company.
All of this has been possible because there are many developers out there for whom Allure Report is a default tool – they are the bedrock of the community.
Conclusion
The structure of Allure Report didn’t appear all at once, like Athena did from the head of Zeus. It took many years of thinking, planning, and re-iterating on community feedback. What emerged as a result was a tool that was purpose-built to be extensible and to smooth out the creation of new integrations. Today, expanding upon this labor means leveraging the code, experience and architectural decisions that have been accumulated over the years.
If you’d like to learn more about Allure Report, we’ve recently created a dedicated site. Naturally, there’s documentation, as well as detailed info on all the integrations (under “Modules”). See if you can find your language and test framework there! And we’re planning to add much more stuff in the future, like guides, so don’t be a stranger and pay us a visit.
Author

Artem Eroshenko
CPO and Co-Founder of Qameta Software
Qameta Software are a Gold Sponsor at AutomationSTAR 20-21 Nov. 2023 in Berlin